Leaky Bucket Rate Limiting and its Queue-Based Variant
A closer look at the Leaky Bucket algorithm, how it works, when to use the queue-based variant, and how to implement it in Java.
Part of the Rate Limiting series
Table of Contents
The Leaky Bucket Rate Limiting algorithm utilizes a FIFO (First In, First Out) queue with a fixed capacity to manage request rates, ensuring that requests are processed at a constant rate regardless of traffic spikes. It contrasts with the Token Bucket algorithm by not allowing for bursty traffic allowances based on token accumulation but instead focusing strictly on maintaining a constant output rate. When the queue is full, incoming requests are denied until space becomes available. This approach effectively moderates the flow of requests, preventing server overload by maintaining a steady rate of processing, akin to a bucket leaking water at a fixed rate to avoid overflow.
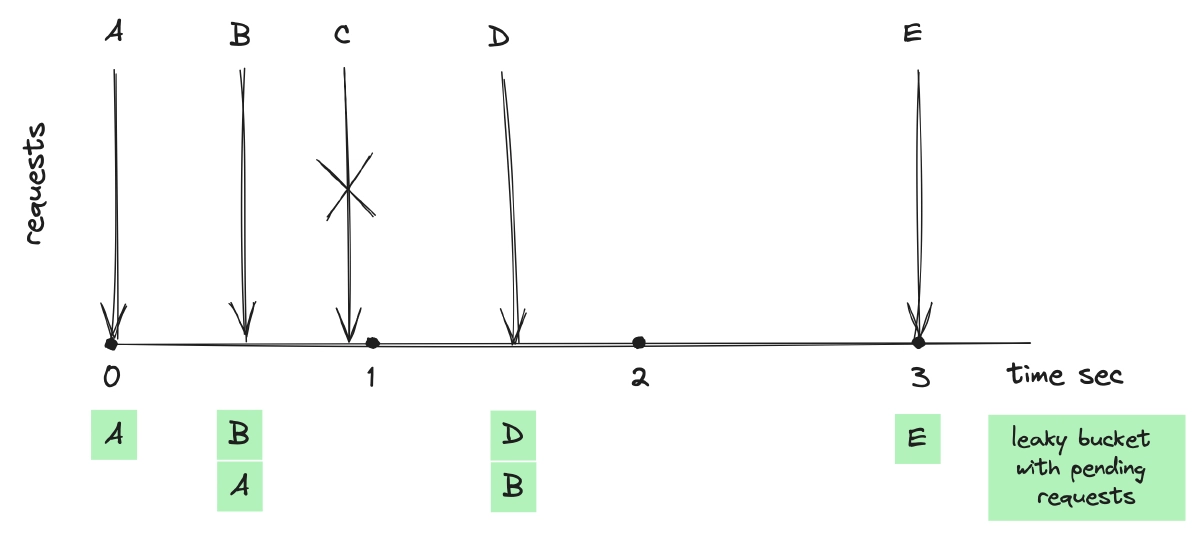
The above diagram shows an algorithm with a rate limit of one request per second and a bucket capacity for two requests. Initially, when request A arrives, it is added to an empty queue and processed. With space for one more, request B is also added, filling the bucket to capacity. Request C is rejected because the bucket is full and hasn’t leaked yet. After one second, a leak removes request A, making room for request D. By the time request E arrives, the bucket is empty due to the leaks for requests B and D, allowing E to be accepted.
Implementing the Leaky Bucket Rate Limiter
This following implementation covers the pure Leaky Bucket Rate Limiter, a no-queue-based implementation focusing on guaranteed rate limiting. In this model, the bucket’s capacity indicates the maximum number of requests that can be “held” at any moment. If a request arrives when the bucket is full (indicating the water level has reached the bucket’s capacity), the request is rejected. This strategy ensures a smooth and predictable output rate, although it may prove restrictive for handling bursty traffic.
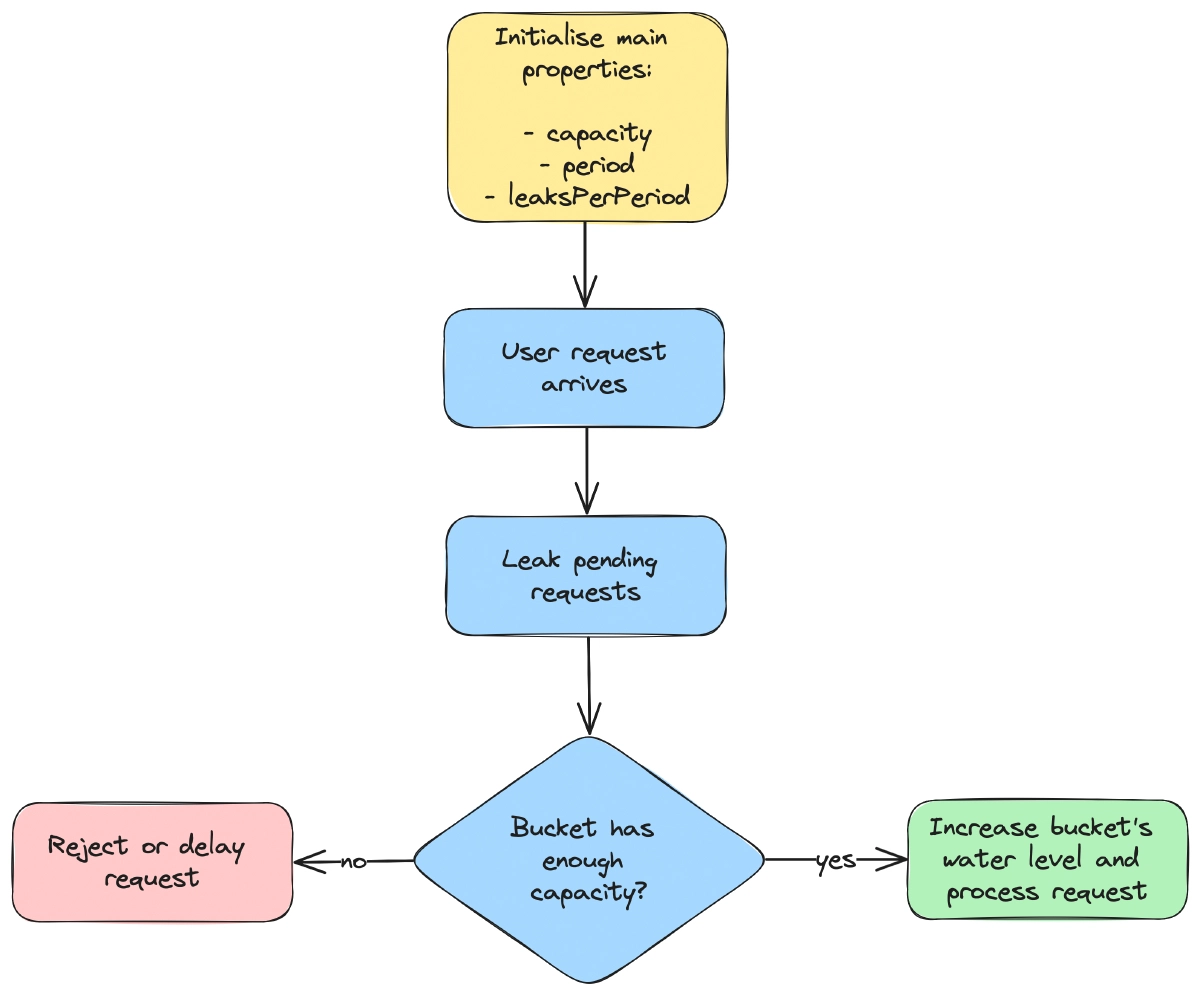
The algorithm initializes with key properties as follows:
- The maximum number of requests a user can make within a specified period before being limited.
- The time period during which requests are evaluated for limiting.
- The number of requests permitted to leak out (be processed) per period.
As shown in the flow diagram below, each incoming request triggers an attempt to leak the bucket, with the number of leaks varying based on the time elapsed since the last leak. If the bucket has enough capacity for the incoming request, the water level in the bucket rises, and the request is processed successfully. Otherwise, the request is either rejected or delayed until enough leakage occurs to lower the water level sufficiently.
To track user-specific buckets, you can use a dictionary that maps each user ID to a pair consisting of the last leak timestamp and the current water level, denoted as Map<String, LeakBucket>.
Below is a Java implementation of the Leaky Bucket Rate Limiting algorithm:
import java.time.Clock;
import java.time.Duration;
import java.util.HashMap;
import java.util.Map;
public class LeakyBucketRateLimiter {
private final int capacity;
private final Duration period;
private final int leaksPerPeriod;
private final Clock clock;
private final Map<String, LeakyBucket> userLeakyBucket = new HashMap<>();
public LeakyBucketRateLimiter(int capacity, Duration period, int leaksPerPeriod, Clock clock) {
this.capacity = capacity;
this.period = period;
this.leaksPerPeriod = leaksPerPeriod;
this.clock = clock;
}
public boolean allowed(String userId) {
LeakyBucket bucket = userLeakyBucket.computeIfAbsent(userId,
k -> new LeakyBucket(clock.millis(), 0));
bucket.leak();
return bucket.processed();
}
private class LeakyBucket {
private long leakTimestamp; // Timestamp of the last leak.
private long waterLevel; // Current water level represents the number of pending requests.
LeakyBucket(long leakTimestamp, long waterLevel) {
this.leakTimestamp = leakTimestamp;
this.waterLevel = waterLevel;
}
/**
* Simulates the leaking of requests over time. This method adjusts the water level
* based on the elapsed time since the last leak, applying the defined leak rate.
*/
void leak() {
long now = clock.millis();
long elapsedTime = now - leakTimestamp;
long elapsedPeriods = elapsedTime / period.toMillis();
long leaks = elapsedPeriods * leaksPerPeriod;
if (leaks > 0) {
waterLevel = Math.max(0, waterLevel - leaks);
leakTimestamp = now;
}
}
/**
* Attempts to process a request by incrementing the water level if under capacity.
*
* @return true if the request is processed (under capacity), false if the bucket is full.
*/
boolean processed() {
if (waterLevel < capacity) {
++waterLevel;
return true;
} else {
return false;
}
}
}
}The allowed method determines if a user’s request falls within the specified limits. For a new user, an empty bucket is created with a zero water level, otherwise, existing bucket is retrieved. The bucket is then leaks based on the elapsed time since the last leak. The method attempts to increase the water level in the bucket to process the current request, allowing the request to pass if a water level doesn’t exceed the bucket’s capacity, otherwise, rejecting it.
Simulating Requests From Multiple Users with Tests
The following Java test demonstrates the usage of this limiter:
import org.junit.jupiter.api.Test;
import java.time.Clock;
import java.time.Duration;
import static org.junit.jupiter.api.Assertions.assertFalse;
import static org.junit.jupiter.api.Assertions.assertTrue;
import static org.mockito.Mockito.mock;
import static org.mockito.Mockito.when;
public class LeakyBucketRateLimiterTest {
private static final String BOB = "Bob";
private static final String ALICE = "Alice";
@Test
void allowed_requestsFromMultipleUsers_ensuresIndividualRateLimiters() {
Clock clock = mock(Clock.class);
when(clock.millis()).thenReturn(0L, 0L, 999L, 1000L, 1000L,
1000L, 1001L, 2001L, 2001L, 2001L, 3002L, 3003L);
LeakyBucketRateLimiter limiter
= new LeakyBucketRateLimiter(1, Duration.ofSeconds(2), 1, clock);
// 0 seconds passed
assertTrue(limiter.allowed(BOB),
"Bob's request 1 at timestamp=0 must pass");
assertFalse(limiter.allowed(BOB),
"Bob's request 2 at timestamp=999 must not be allowed," +
" because bucket has reached its max capacity and no leaks occurred");
// 1 second passed
assertFalse(limiter.allowed(BOB),
"Alice's request 3 at timestamp=1000 must not be allowed," +
" because bucket has reached its max capacity and no leaks occurred");
assertTrue(limiter.allowed(ALICE),
"Alice's request 1 at timestamp=1000 must pass");
assertFalse(limiter.allowed(ALICE),
"Alice's request 2 at timestamp=1001 must not be allowed," +
" because bucket has reached its max capacity and no leaks occurred");
// 2 seconds passed
assertFalse(limiter.allowed(ALICE),
"Alice's request 3 at timestamp=2001 must not be allowed," +
" because bucket has reached its max capacity and no leaks occurred");
assertTrue(limiter.allowed(BOB),
"Bob's request 4 at timestamp=2001 must pass," +
" because bucket leaked 1 request since the last leak timestamp=0" +
" making capacity for 1 request");
assertFalse(limiter.allowed(BOB),
"Bob's request 5 at timestamp=2001 must not be allowed," +
" because bucket has reached its max capacity and no leaks occurred");
// 3 seconds passed
assertTrue(limiter.allowed(ALICE),
"Alice's request 4 at timestamp=3002 must pass," +
" because bucket leaked 1 request since the last leak timestamp=1000" +
" making capacity for 1 request");
assertFalse(limiter.allowed(ALICE),
"Alice's request 5 at timestamp=3003 must not be allowed," +
" because bucket has reached its max capacity and no leaks occurred");
}
}This test simulates scenarios for different users and varying time intervals to ensure the rate limiter functions as expected. More tests and latest source code can be found in the rate-limiting GitHub repository .
For additional implementations and insights, you can explore open-source resources such as:
- High Performance Rate Limiting MicroService and Library
- The ngx_http_limit_req_module uses leaky bucket method
Leaky Bucket Algorithm: Queue-Based Approach
This alternative to the pure Leaky Bucket algorithm, commonly referred to as the Leaky Bucket with queue, includes a FIFO queue with fixed capacity and aims to better handle bursty traffic patterns.
Here’s how it works:
- The queue acts as a buffer for incoming requests.
- When a request arrives, it’s added to the back of the queue.
- Periodically, the “leak” process removes and processes the request at the front of the queue at the configured leak rate.
- If the queue is full when a new request arrives, that request is rejected.
Both the pure and queue-based implementations are valid approaches to the Leaky Bucket algorithm. The choice between them depends on specific requirements:
- For prioritizing a strict and guaranteed rate limit, the pure Leaky Bucket might be more suitable.
- To manage bursty traffic patterns while maintaining an average rate limit, the Leaky Bucket with queue offers a more adaptable solution.
Trade-Offs and Design Considerations
Pros
Simplicity: The leaky bucket algorithm is conceptually straightforward and relatively easy to implement making it a good choice for scenarios where complexity needs to be minimized.
Data Flow Consistency: The leaky bucket enforces a strict output rate. Traffic is released at a constant pace, regardless of incoming bursts. This is ideal for situations where maintaining a smooth and predictable flow of requests is critical, such as preventing denial-of-service attacks or protecting servers from overload.
Efficiency: Operating with a constant queue size, the leaky bucket algorithm is memory efficient. This efficiency is vital for maintaining a uniform flow of requests to the server without requiring significant additional memory resources, making it suitable for systems with limited memory.
Cons
Bursty Traffic: The algorithm’s fixed capacity can struggle with sudden bursts of traffic, leading to potential request rejections if the burst exceeds the bucket’s capacity. This limitation can affect applications that experience occasional spikes in demand.
Fairness: A sudden influx of requests can quickly fill the bucket, leading to the starvation of new requests and uncertainty regarding the processing time for accepted requests.
Underutilization: During periods of low traffic, the fixed rate processing can lead to underutilization of available bandwidth or server resources, as the system continues to process requests at the predetermined rate, regardless of actual demand, potentially leading to inefficiencies.
Common Use Cases
The leaky bucket algorithm is widely utilized for its ability to efficiently handle network traffic, ensuring that data flows smoothly without overwhelming network capabilities. Primarily used in applications requiring consistent data transmission, such as video streaming and telecommunications, it plays a critical role in enhancing user experiences by avoiding network congestion. Its importance is especially recognized in environments where maintaining network performance and preventing disruptions due to data overload are crucial.
Moreover, the Leaky Bucket algorithm’s adaptability is evident in its application across various fields, not just in network traffic management but also in controlling API rate limits. An example of its effective use is by Shopify, which employs the algorithm to regulate its API rate limits, as detailed in their developer documentation . This highlights the algorithm’s ability to ensure equitable resource allocation and prevent resource overuse, underscoring its wide relevance and effectiveness in many technological areas.
Summary
The Leaky Bucket Rate Limiting algorithm provides an effective way to manage network traffic, ensuring a consistent request processing rate to mitigate spikes and avoid server overload. While its simplicity and fixed output rate approach facilitate predictable request flows, ideal for handling variable traffic, this method comes with trade-offs. Specifically, its fairness limitation to prioritise less recent requests can lead to the starvation of new requests, and during periods of low traffic, it may not utilize available bandwidth fully, potentially leading to inefficiencies.