Rate Limiting Concepts and Use Cases
An overview of core rate limiting concepts, common use cases, and how different strategies help control system load and ensure fair usage.
Part of the Rate Limiting series
Table of Contents
Rate limiting is a critical technique in system design that controls the flow of data between systems, preventing resource monopolization, and maintaining system availability and security.
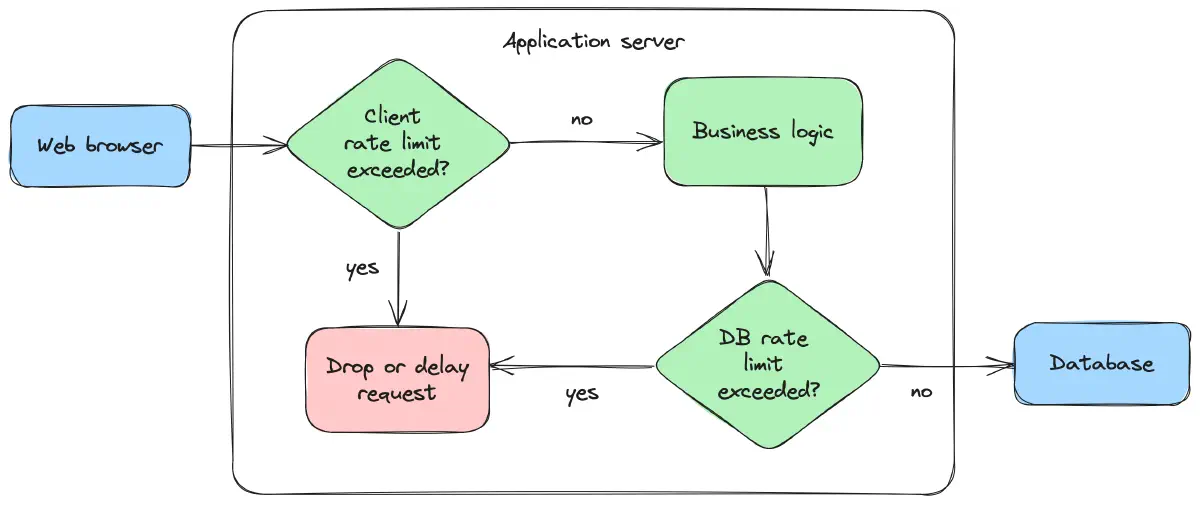
At its core, rate limiting sets a threshold on how often a user or system can perform a specific action within a set timeframe. Examples include limiting login attempts, API requests, or chat messages to prevent abuse and overloading.
Why is rate limiting important?
Defense Against Attacks: It’s an effective barrier against various cyber threats like Denial of Service (DoS) and brute-force attacks, by limiting the rate at which requests are processed.
Operational Efficiency: Rate limiting optimizes resource usage and reduces operational costs, especially in cloud environments where resources are metered.
User Experience and SEO: By preventing server overloads, rate limiting ensures smoother web page loading, enhancing user experience and potentially improving search engine rankings.
Common use cases
Cloud and API Services like Cloudflare use rate limiting to safeguard against DDoS attacks and other malicious traffic from overwhelming application servers. APIs often impose limits as a means to encourage upgrades to higher subscription tiers.
Email Services like Gmail implement rate limiting to prevent spam , thereby maintaining the credibility of their service.
Social Media and Messaging like Telegram use it to control bots , ensuring fair usage for all users.
Streaming Services like Netflix implement rate limiting to manage server-client traffic. This can involve limiting the bitrate or the number of concurrent streams , which helps prevent server overloads and improves the user experience.
Distributed Systems use rate limiting to smooth traffic between nodes and prevent bottlenecks that could make the system unusable. This may include limiting the number of messages between services or the number of concurrent connections to a database.
Network Traffic is often rate-limited to prioritize certain types of traffic, thereby enhancing overall network efficiency.
Types of rate limits
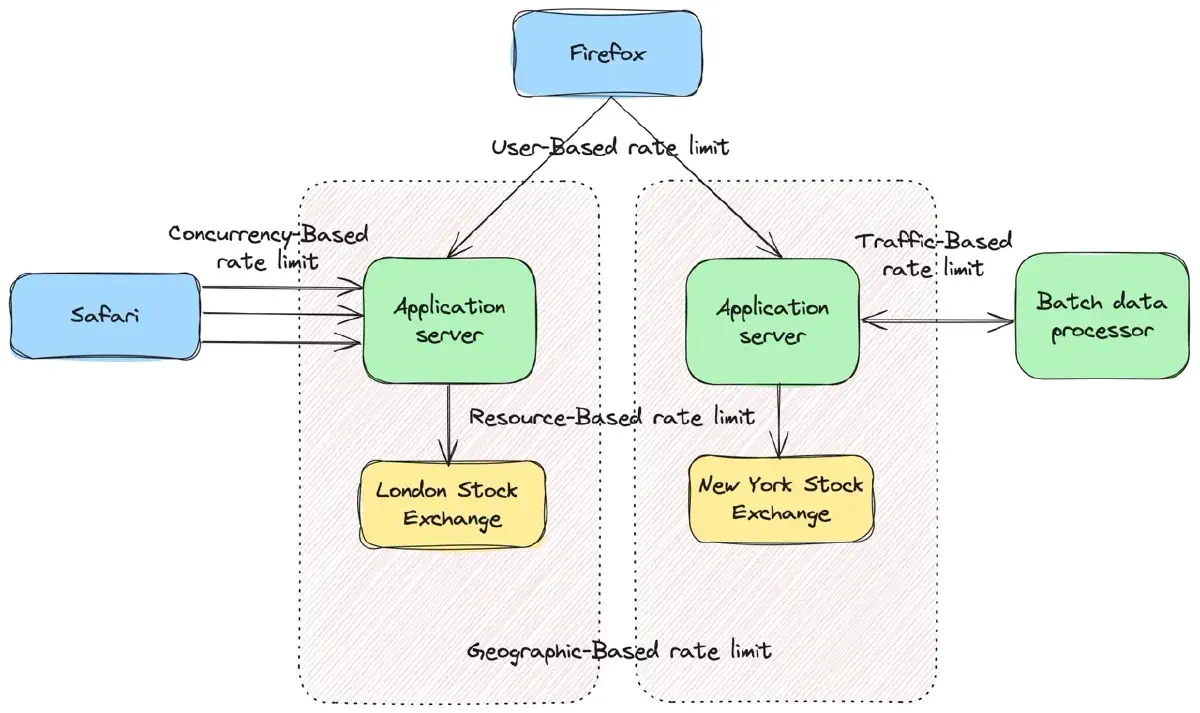
User-Based: This method caps the number of requests a user can make in a given timeframe. If the user exceeds the limit, their subsequent requests are either dropped or delayed until the next timeframe. Users are usually identified by an IP address or an API key.
Resource-Based: This approach limits the number of requests to a specific server resource.
Traffic-Based: This type limits the amount of data transmitted over a network. It can be used to prioritize different types of traffic, such as prioritizing real-time data over batch processing.
Geographic-Based: This strategy implements different limits based on geographic locations and timeframes. For example, consider two application servers, as shown in Figure 2: one in New York, using the New York Stock Exchange, and another in London, using the London Stock Exchange. Since the London Stock Exchange operates Monday through Friday from 8:00 AM to 4:30 PM GMT, the server in London may experience high user activity during these hours. Therefore, you might set a higher rate limit for your London server during this period and lower it outside these hours. This approach helps detect and prevent suspicious traffic.
Concurrency-Based: This method sets a maximum number of parallel sessions or connections per user. It is useful in mitigating distributed denial-of-service (DDoS) attacks.
Rate limiting algorithms
Fixed window
Fixed Window divides time into fixed windows of specified duration. Each window has a limit on the number of requests it can handle, and requests are counted against this limit. The request count is reset at the beginning of each new window.
In the figure below, the rate limit is set to one request per two seconds. Request B is dropped because the request counter reaches two in the current two-second timeframe. The next timeframe resets the request count, allowing Request C to be processed.
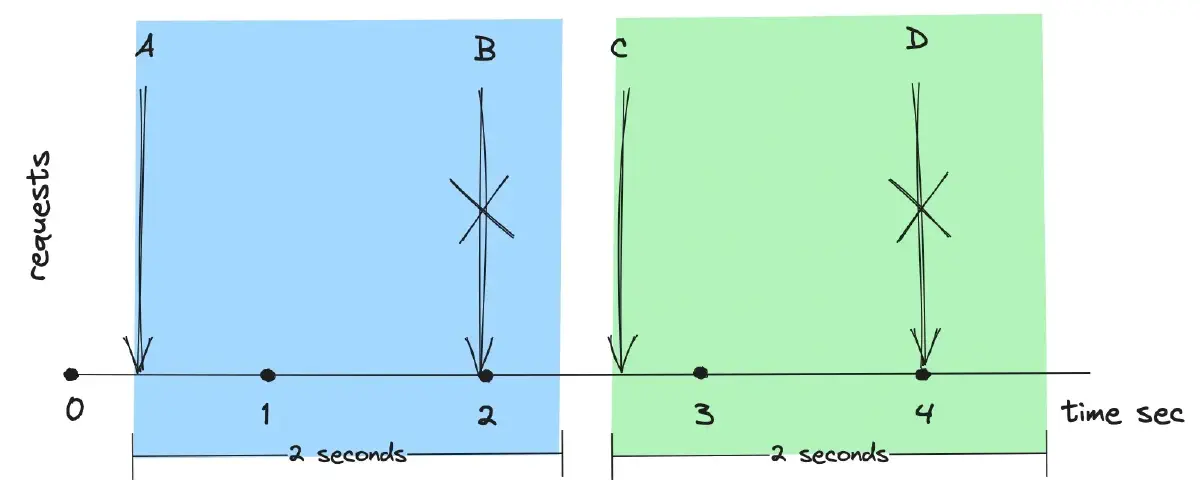
This algorithm is applied in scenarios where rate limits need to be enforced within specific time intervals, such as in API rate limiting and user authentication.
Sliding window
Sliding Window is similar to fixed-window rate limiting, but it differs in that the time window slides forward continuously, instead of being fixed and reset. This approach tracks the number of operations within the current time window and adjusts as time progresses.
In Figure 4, requests B and C are dropped because the moving two-second windows ending at the timestamps of requests B and C still include the processed request A. The timeframe ending with the timestamp of request D does not include request A, as it is too far in the past, thus allowing request D to be processed.
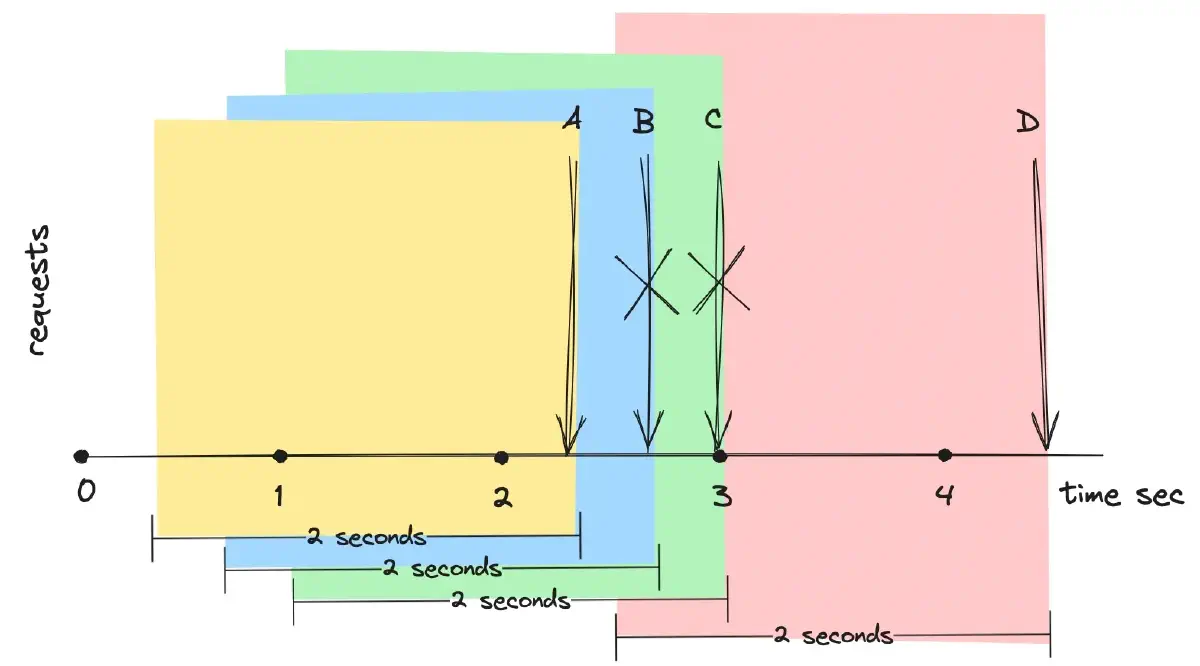
This algorithm is effective in scenarios where there is a need to track and limit the rate of operations over a dynamic timeframe.
Token bucket
Token Bucket involves a bucket that is filled with tokens at a fixed rate. Each token represents permission for an action. Requests are allowed if there are available tokens in the bucket; otherwise, they are delayed or dropped, as shown in Figure 5.
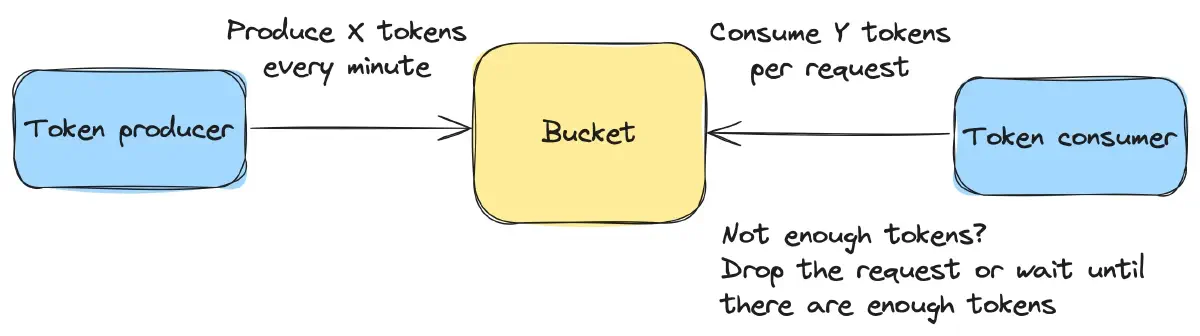
This algorithm is commonly used in network traffic shaping, API rate limiting, and resource access control.
Leaky bucket
Leaky Bucket is represented by a bucket with a leak, emptying its contents at a constant rate. Incoming requests are added to the bucket, functioning as a queue. If the bucket overflows, new requests are either delayed or discarded, as illustrated in Figure 6.
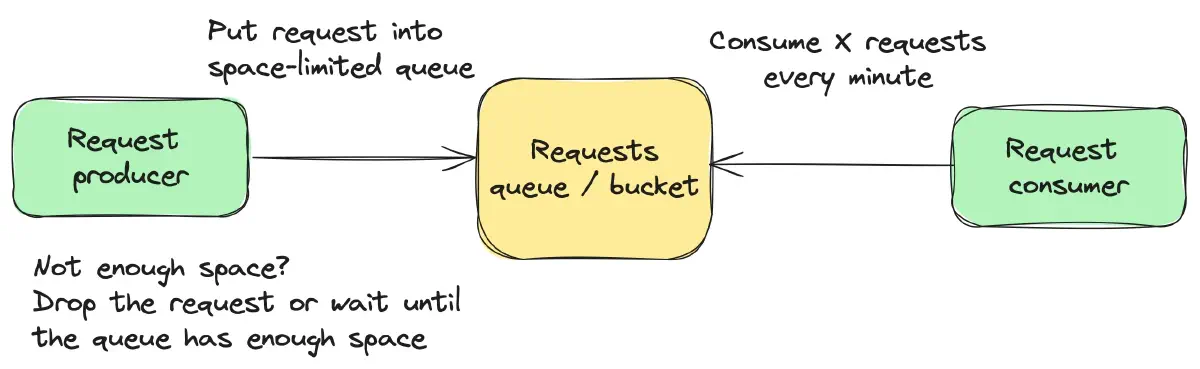
This algorithm is typically used to smooth out traffic patterns, prevent bursts in data transmission, and control the rate of data processing.
Adaptive rate limiting dynamically adjusts rate limits based on current system conditions, user behavior, or other contextual factors. This approach is particularly effective in scenarios where rate limits need to be flexible and adapt to changing conditions, such as in content delivery networks (CDNs) or real-time systems.
Distributed rate limiting is typically built on top of the aforementioned algorithms and used in distributed systems where rate limits are enforced across multiple servers or nodes. Each server may maintain its local rate limits, and a centralized mechanism can coordinate or aggregate these limits. This method is suitable for microservice architectures and scenarios where rate limiting needs to be coordinated across multiple components.
Rate limiting vs. throttling
While rate limiting focuses on establishing a strict quantitative limit on the number of operations within a specified timeframe, throttling is a broader concept focused on controlling the data flow in a more dynamic and adaptive manner. Throttling may involve rate limiting but can also include other measures, such as load shedding and backpressure, to manage resource utilization.
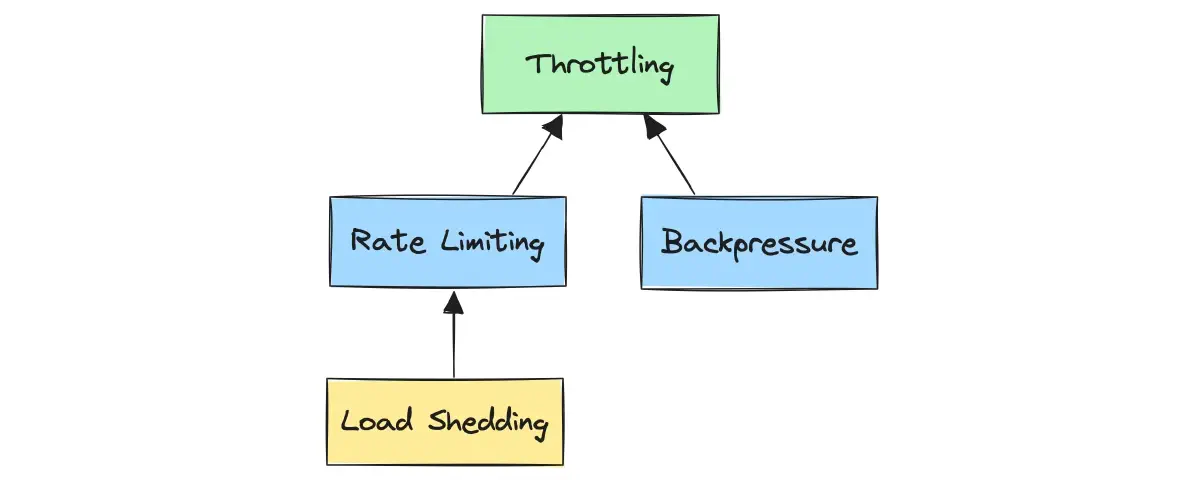
Rate limiting, load shedding, and backpressure can be considered specific types of throttling, each focusing on one aspect of resource management.
Rate limiting vs. load shedding
Load shedding is a form of rate limiting based on the overall system state, where lower-priority requests are discarded to maintain critical functions. An illustrative example is Stripe’s implementation of two load shedders in their system, as detailed in Stripe’s blog on rate limiters . This approach enhances API availability and prioritizes critical traffic over lower-priority requests.
Fleet usage load shedder. Using this type of load shedder ensures that a certain percentage of your fleet will always be available for your most important API requests. We divide up our traffic into two types: critical API methods (e.g. creating charges) and non-critical methods (e.g. listing charges.) We have a Redis cluster that counts how many requests we currently have of each type. We always reserve a fraction of our infrastructure for critical requests. If our reservation number is 20%, then any non-critical request over their 80% allocation would be rejected with status code 503.
Worker utilisation load shedder. Most API services use a set of workers to independently respond to incoming requests in a parallel fashion. This load shedder is the final line of defense. If your workers start getting backed up with requests, then this will shed lower-priority traffic. We divide our traffic into 4 categories: Critical methods, POSTs, GETs, Test mode traffic. We track the number of workers with available capacity at all times. If a box is too busy to handle its request volume, it will slowly start shedding less-critical requests, starting with test mode traffic. If shedding test mode traffic gets it back into a good state, great! We can start to slowly bring traffic back. Otherwise, it’ll escalate and start shedding even more traffic.
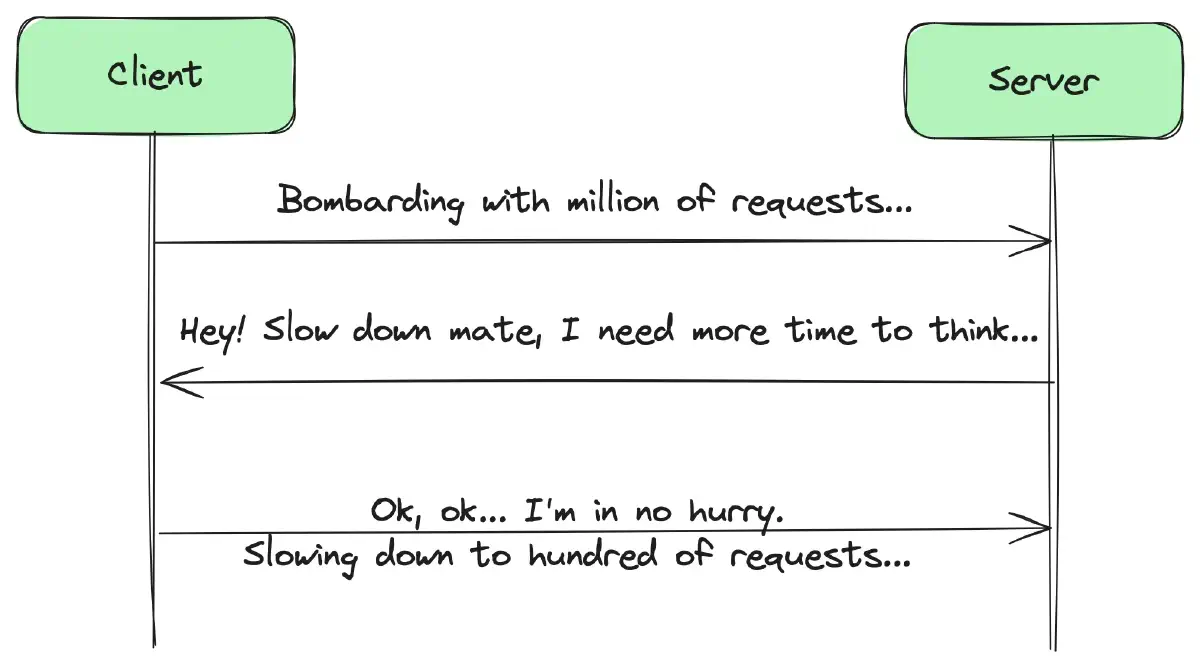
Rate limiting vs. backpressure
Backpressure is a mechanism that signals upstream components to slow down or stop producing data when downstream components are unable to handle the current rate. It involves a combination of client-side and server-side mechanisms. On the server side, backpressure includes rate limiting, while on the client side, it involves understanding how to adjust the request rate based on server load.
Challenges and limitations
Setting the appropriate rate limits can be a challenging task. If the limits are set too low, they can unnecessarily restrict legitimate users; however, if they are set too high, they might not effectively prevent system abuse.
Another consideration is managing sudden surges in legitimate traffic, such as during special events or promotions. Such spikes can lead to genuine requests being wrongly blocked, negatively affecting the user experience.
In a distributed system environment, ensuring consistent and effective rate limiting across multiple servers or geographic locations can be a complex task, requiring intelligent coordination.
Implementing rate limiting involves balancing security and usability. It’s also important to consider the impact of the algorithm on both system performance and the user experience.
Summary
Rate limiting is not a silver bullet against all security issues, but it is a fundamental part of a multi-layered defense strategy. It plays an essential role in maintaining system integrity, optimizing costs, and ensuring a seamless user experience. As technologies evolve, so too do the methods and strategies for effective rate limiting, making it a continually relevant topic for software engineers.